
Tags
Technology has changed our way of researching and our reading habit after the Internet became the popular platform for the release of news and information. The documents and publications from the non-information era are still invaluable for us especially when it comes to referencing and history learning. Yet, these resources are black and white and read all over, which does not fit in today’s mode of information processing. To digitalise these old documents, four students from Baptist University (BU) learned about the technique and usage of software in Optical Character Recognition (OCR) workshop.

Using OCR machine to preserve information on old documents.
1. Scanning

Zeutschel, a German brand OCR scanner.

The wide platen of the scanner for putting items-to-be-scanned.
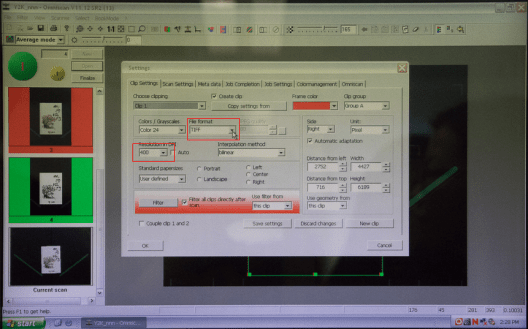
Save the scanned document with the setting of TIFF file format and resolution at 400 DPI.

The handle for controlling the glass which covers the items-to-be-scanned on the platen.
2. Processing of document preservation (Optical Character Recognition)
To best suit library’s needs, they use a software named ABBYY FineReader here to processing the scanned files, making PDF images them into searchable/editable files and text.
2.1 Open and Save
a. Open “PDF/image” you scanned before(best use the uncompressed PDF)
b. Before proofreading, save FineReader Document into folder where is should be.
c. After proofreading, report txt per page(create a separate file for each page) and PDF/A per volume(create a single file for all pages).
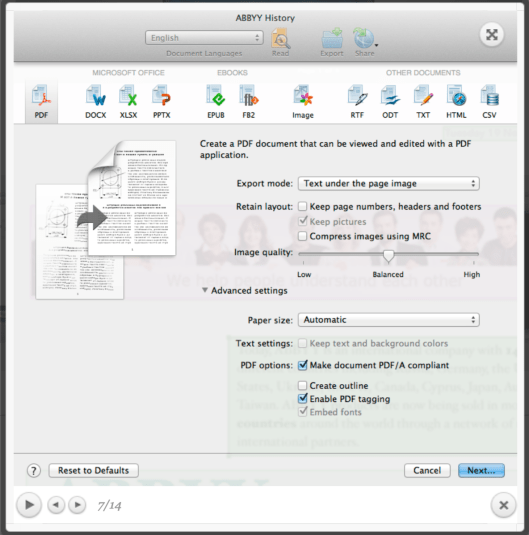
2.2 Processing
a. set default languages.
b. Area properties(ordering and direction of text, etc.).
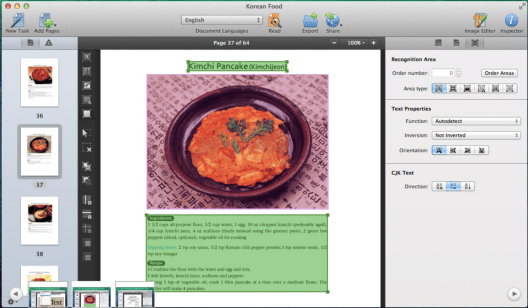
2.3 Draw the areas
a. select text area
b. delete all selected picture area(the red box).
c. use table area for table and complicated structure.
d. check the order of areas, make sure it’s consistent with the text.
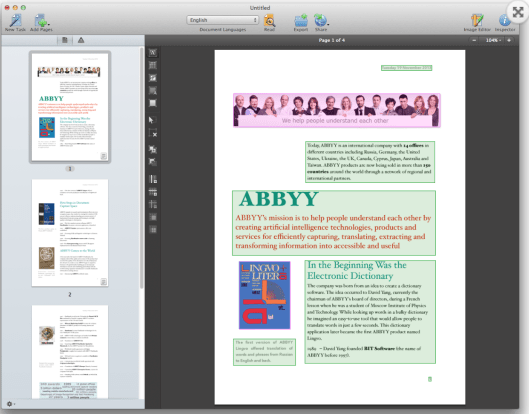
2.4 Image editors
a. use preprocess, Deskew, Straighten Text, etc.
2.5 Style editor
a. Chinese Front: SimHei
b. Size: 8-12
c. Merge default style
2.6 Content(check these things)
a. Name&Title
b. Table of content
c. Date
2.7 Export
a. Export three files(TEXT, PDF and abbff.format).
3. Works have done so far
The library in HKBU has conducted various projects such as Preservation for the Documentation of Chinese Christianity, which aims to preserve and make accessible books, periodicals, reports and archival materials that document Chinese Christianity by digitization and microfilming. Typical display methods for those digital publications can be searchable PDF, which can be done by OCR, and flipbook-like display through software such FlippingBook. Also, some digital archives are stored as a database for users to search according to different conditions.

Preservation for the Documentation of Chinese Christianity, one of the document-preservation scheme launched by HKBU.
ORC scanners can turn scanned documents into a searchable pdf format.
Considering different user groups and the nature of different projects, readers can choose the best way to display the content.
Remarks from lecturer
It is our pleasure to learn that HKBU Library has a lot overlapping works with our data journalism process. Data collection is the very first step in data journalism production process. It largely determines what news one can or can not find, especially when one day everyone in the industry is equipped with data analysis and data visualisation skills. We often find government records coming in form of scanned PDF or even as printed documents in their library. Scanning and applying OCR on those documents can help journalists to turn the records into digital and searchable format. The scanning step is easy to find alternatives. One can find desktop scanners in most labs. Or one can use cell phone to take photos. Evernote can use computer graphics algorithm to polish photos as if they are generated by a scanner. The OCR step is more heavy duty and requires professional software, e.g. ABBYY FineReader adopted by HKBU library. Those tech savvy users can checkout tesseract-ocr, the widely used open source library & command line which has 16K+ stars on GitHub as of this writing.
— Pili Hu (Mar 4, 2018)
Points to consider during scanning:
- Lighting
- Folding
- Resolution (400dpi for OCR, 600dpi for artworks)
Points to consider during OCR:
- Orientation of texts
- Deal with different font-face, especially Chinese characters
- Recognise characters in pictures or not (e.g. photo of a banner in news story)
- Check and manually fix wrong recognitions (accuracy)
- Title, name and author are high priority information
- Label, break or merge areas of texts
Text / Celia Lai, Maggie Liu, Ivy Wang
Photos / Maggie Liu, Ivy Wang, Erin Chan
Editor / Pili Hu
