Tags
Aimee Edmondson is now an Associate Professor with Scripps School of Journalism, Ohio University. HKBU students are very lucky to have this knowledgeable and passionate speaker to talk about data journalism this afternoon. Her 12 years in reporting and later acquired statistics and technology are a fine combination for a data journalist. In the world where people are too fascinated by new technology and numerous boot camps are created by non-journalists, Aimee can be a role model for those “traditional journalists” who are moving in this direction.
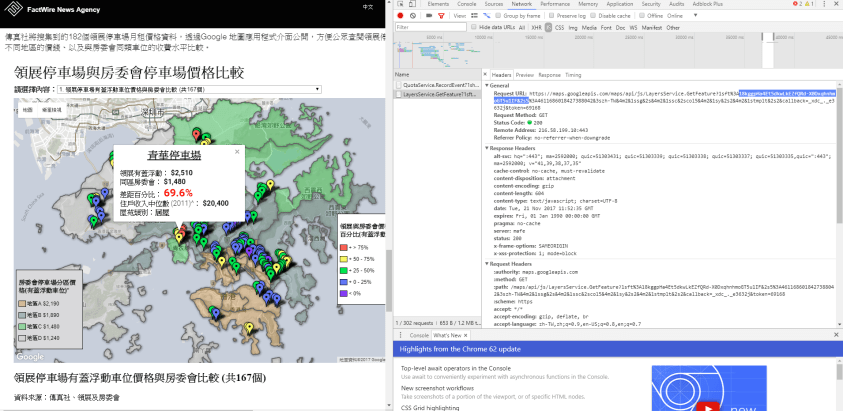
Why does data matter? In Aimee’s words, you want to be a reporter, not a repeater. Data helps one to verify what the source is saying and find out what is really happening. To be pragmatic, we are seeing more and more JD requiring data analytics skills from investigative reporters. Going beyond the journalism domain, the skills trained by data journalism can well fit into corporate communication, public relation and advertising industry.
To start, one only needs to work on “small data”, with a spreadsheet.