
This is a casual post to dump some target sites for scraping or just project ideas. Those messages were first sent through COMM7780/JOUR7280 WeChat group. Although we have only explored part of those possibilities this semester, the list is good for future reference. We can bounce off ideas in the comment below and enrich this list.
Top Targets: Movie, Shopping and News
Let’s first have a look at what the students care about from HW2 submission:
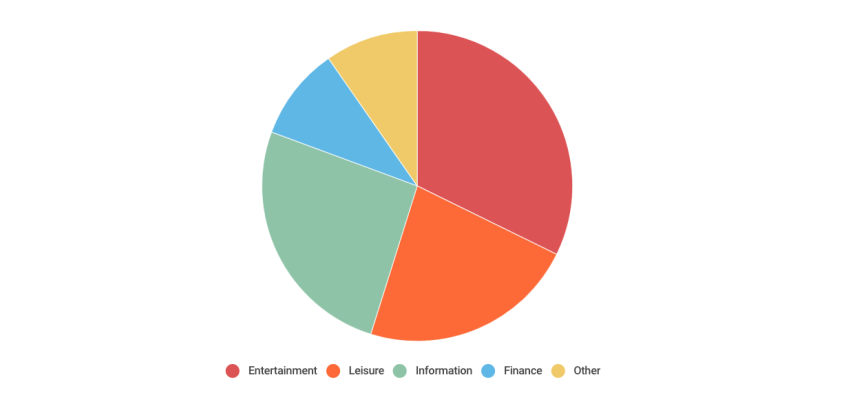
Scraping Targets from HW2 submission – COMM7780/JOUR7280
Entertainment and Leisure made up most of the submissions, among which movie rating sites are popular targets. There are 7 students in total who scraped movie rating sites like Douban, Rotten Tomato and IMDB. The leisure category contains online shopping, travel and food review. As to information category, the most popular targets are different news sites. This distribution of interest roughly matches the examples we gave in class: Initium Lab (News), IMDB (Entertainment) and OpenRice (Leisure). The following table shows more details.
| Mega Type | Type | Count |
| Entertainment | Movie | 7 |
| Music | 3 | |
| Information | News Site | 5 |
| Job List | 2 | |
| Social Network | 1 | |
| Leisure | E-Commerce | 4 |
| Travel Site | 2 | |
| Food Review | 1 | |
| Other | Other | 3 |
| Finance | Real Estate Market | 2 |
| Stock Market | 1 |
Some Scraping Ideas from for future reference
[scraping idea] http://www.emojination.org/ – an NGO that pushes adoption of emoji in Unicode standard. Can try to analyse who propose what and factor to affect acceptance.
[scraping idea] https://www.squarefoot.com.hk/haunted/ – a list of haunted houses in Hong Kong. A group of DJ students last term used scrapinghub.com to crawl the data . Now you can write Python codes with fine control. There are two more databases for you to cross-check https://news.gohome.com.hk/tc/category/haunted-house/haunted-house-article/ and http://www.hkea.com.hk/UHousesServ
[scraping idea] Hillary Clinton email archive from WikiLeaks: https://www.wikileaks.org/clinton-emails/emailid/20000 . A bit text processig is needed to turn the scraped data into structured format.
[scraping idea] You have agreed but never read those lengthy Terms Of Service (TOS). Here are the quick comparisons: https://tosdr.org/ . One can crawl by service, by topic, by certain term.
[scraping idea] Media, as the forth power, always lack supervision. The “newsdiff” project from Taiwan’s g0v monitors EVERY modifications of articles on mainstream media: http://newsdiff.g0v.ronny.tw/ . Option 1: crawl the TW’s newsdiff and analyse whether those are minor revisions, or black-and-white changes. Option 2: build the Hong Kong version of newsdiff by scraping all local media
[scraping idea] Hacker News is the world number 1 technology news crowd gathering service: https://news.ycombinator.com/ . One can sense the trend from those articles shared by mostly guru users.
[scraping idea] https://juejin.im/ is the Chinese counterpart of Hacker News. One can check the difference of topic popularity between HN and juejin, in past 5-10 years, and answer the question: is China switching from a copycat role to a leading role.
[scraping idea] WikiCFP is a wiki style Call-For-Paper site, actively used by computer science researchers. You can get the name, time, location of those conferences. One can create a time-based map viz later. See a search result of SIGCOMM here.
[scraping idea] Online News Association has a career center for member organisations. You will find many job postings from the top media in the world. One can scrape the JDs and run text analysis (with a bit Week 7’s knowledge) similar to the Tencent post above. http://careers.journalists.org/jobs/10753217/graphics-journalist
[scraping idea] 新闻联播 is one of the most important windows to peek into China’s major moves. The transcript of the national broadcasting is available online for you to scrape. One quick finding in an early Initium Lab’s hackathon is the correlation between # of mentions of “entrepreneurship” and volatility of startup board of stocks. It’s a huge gold mine. The dataset is too large to host online, but Initium Lab has already published the scripts. It is also good reference to learn different situations to handle during scraping, e.g. pagination, different verisons of websites.
